python 入門
前言
前陣子買了幾本python的書
連續假期終於有空看了這些書
發現要打個for 都還要看書看一下怎們打
也常常打到最後都加上;
紀錄一下一些用法與說明讓自己方便查詢
花了好幾個小時終於把他打完了..
程式語言邏輯上其實都是一樣的
這篇對於沒學過程式語言的想學python 也是很棒的
寫過程式語言的 剛踏入python 也是很有幫助的
python 變數 資料類型
Python中資料類型
1.整數
Python可以處理任意大小的整數,當然包括負整數,在Python程序中,整數的表示方法和數學上的寫法一模一樣,例如:
1,100,-8080,0,等。
計算機由於使用二進制,所以,有時候用十六進製表示整數比較方便,十六進制用0x前綴和0-9,a-f表示,例如:0xff00,0xa5b4c3d2,等等。
|
|
結果
652802780087250
2.浮點數
浮點數也就是小數,之所以稱為浮點數,是因為按照科學記數法表示時,一個浮點數的小數點位置是可變的,比如,1.23x10^9和12.3x10^8是相等的。浮點數可以用數學寫法,如
1.23,3.14,-9.01,等等。但是對於很大或很小的浮點數,就必須用科學計數法表示,把10用e替代,1.23x10^9就是1.23e9,或者12.3e8,0.000012可以寫成1.2e-5,等等。
整數和浮點數在計算機內部存儲的方式是不同的,整數運算永遠是精確的(除法難道也是精確的?是的!),而浮點數運算則可能會有四捨五入的誤差。
3.字串
字串是以
''或""括起來的任意,比如'abc',"xyz"等等。請注意,’’或””本身只是一種表示方式,不是字串的一部分,因此,字串’abc’只有a,b,c這3個字符。
4.布林值
布林值和布爾代數的表示完全一致,一個布林值只有True、False兩種值,
True,False,在Python中,可以直接用True、False表示布林值(請注意大小寫),也可以通過布爾運算計算出來。
布林值可以用and、or和not運算。
and運算是與運算,只有所有都為 True,and運算結果才是 True。
or運算是或運算,只要其中有一個為 True,or 運算結果就是 True。
not運算是非運算,它是一個單目運算符,把 True 變成 False,False 變成 True。
5.空值
空值是Python裡一個特殊的值,用None表示。 None不能理解為0,因為0是有意義的,而None是一個特殊的空值。
此外,Python還提供了列表、字典等多種數據類型,還允許創建自定義數據類型,
python print
print語句也可以跟上多個字串,用逗號“,”隔開,就可以連成一串輸出:
結果
The quick brown fox jumps over the lazy dog The quick brown fox jumps over the lazy dog
- print會依次列印每個字串,遇到逗號“,”會輸出一個空格,因此,輸出的字串是這樣拼起來的:
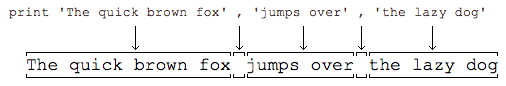
python中定義字串
如果字串既包含'又包含"怎麼辦?
這個時候,就需要對字串的某些特殊字符進行“轉義”,Python字串用\進行轉義。
要表示字串 Bob said “I’m OK”.
由於 ‘ 和 “ 會引起歧義,因此,我們在它前面插入一個\表示這是一個普通字符,不代表字串的起始,因此,這個字串又可以表示為
‘Bob said \”I\’m OK\”.’
注意:轉義字符 \ 不計入字串的內容中。
常用的轉義字符還有:
\n 表示換行
\t 表示一個製表符
\ 表示 \ 字串本身
Python中raw字串與多行字串
如果一個字串包含很多需要轉義的字符,對每一個字符都進行轉義會很麻煩。為了避免這種情況,我們可以在字串前面加個前綴 r ,表示這是一個 raw 字串,裡面的字符就不需要轉義了。例如:
r’(~~)/ (~~)/‘
但是r'...'表示法不能表示多行字串,也不能表示包含'和"的字串(為什麼?)
如果要表示多行字串,可以用'''...'''表示:
‘’’Line 1
Line 2
Line 3’’’
上面這個字串的表示方法和下面的是完全一樣的:
‘Line 1\nLine 2\nLine 3’
還可以在多行字串前面添加 r ,把這個多行字串也變成一個raw字串:
r’’’Python is created by “Guido”.
It is free and easy to learn.
Let’s start learn Python in imooc!’’’
Python中Unicode字串
字串還有一個編碼問題。
因為計算機只能處理數字,如果要處理文本,就必須先把文本轉換為數字才能處理。最早的計算機在設計時採用8個比特(bit)作為一個字節(byte),所以,一個字節能表示的最大的整數就是255(二進制11111111=十進制255),0 - 255被用來表示大小寫英文字母、數字和一些符號,這個編碼表被稱為ASCII編碼,比如大寫字母A 的編碼是65,小寫字母z 的編碼是122。
如果要表示中文,顯然一個字節是不夠的,至少需要兩個字節,而且還不能和ASCII編碼衝突,所以,中國製定了GB2312編碼,用來把中文編進去。
類似的,日文和韓文等其他語言也有這個問題。為了統一所有文字的編碼,Unicode應運而生。 Unicode把所有語言都統一到一套編碼裡,這樣就不會再有亂碼問題了。
Unicode通常用兩個字節表示一個字符,原有的英文編碼從單字節變成雙字節,只需要把高字節全部填為0就可以。
因為Python的誕生比Unicode標準發布的時間還要早,所以最早的Python只支持ASCII編碼,普通的字串'ABC'在Python內部都是ASCII編碼的。
Python在後來添加了對Unicode的支持,以Unicode表示的字串用u’…’表示,比如:
print u’中文’
中文
注意: 不加 u ,中文就不能正常顯示。
Unicode字串除了多了一個 u 之外,與普通字串沒啥區別,轉義字符和多行表示法仍然有效:
轉義:
u’中文\n日文\n韓文’
多行:
u’’’第一行
第二行’’’
raw+多行:
ur’’’Python的Unicode字串支持”中文”,
“日文”,
“韓文”等多種語言’’’
如果中文字串在Python環境下遇到 UnicodeDecodeError,這是因為.py文件保存的格式有問題。可以在第一行增加註釋
–coding: utf-8–
目的是告訴Python解釋器,用UTF-8編碼讀取源代碼。然後用Notepad++ 另存為… 並選擇UTF-8格式保存。
Python中整數和浮點數
Python支持對整數和浮點數直接進行四則混合運算,運算規則和數學上的四則運算規則完全一致。
基本的運算:
1 + 2 + 3 # ==> 6
4 * 5 - 6 # ==> 14
7.5 / 8 + 2.1 # ==> 3.0375
使用括號可以提升優先級,這和數學運算完全一致,注意只能使用小括號,但是括號可以嵌套很多層:
(1 + 2) 3 # ==> 9
(2.2 + 3.3) / (1.5 (9 - 0.3)) # ==> 0.42145593869731807
和數學運算不同的地方是,Python的整數運算結果仍然是整數,浮點數運算結果仍然是浮點數:
1 + 2 # ==> 整數 3
1.0 + 2.0 # ==> 浮點數 3.0
但是整數和浮點數混合運算的結果就變成浮點數了:
1 + 2.0 # ==> 浮點數 3.0
為什麼要區分整數運算和浮點數運算呢?這是因為整數運算的結果永遠是精確的,而浮點數運算的結果不一定精確,因為計算機內存再大,也無法精確表示出無限循環小數,比如 0.1 換成二進製表示就是無限循環小數。
那整數的除法運算遇到除不盡的時候,結果難道不是浮點數嗎?我們來試一下:
11 / 4 # ==> 2
令很多初學者驚訝的是,Python的整數除法,即使除不盡,結果仍然是整數,餘數直接被扔掉。不過,Python提供了一個求餘的運算 % 可以計算餘數:
11 % 4 # ==> 3
如果我們要計算 11 / 4 的精確結果,按照“整數和浮點數混合運算的結果是浮點數”的法則,把兩個數中的一個變成浮點數再運算就沒問題了:
11.0 / 4 # ==> 2.75
Python中布爾類型
我們已經了解了Python支持布爾類型的數據,布爾類型只有True和False兩種值,但是布爾類型有以下幾種運算:
- and 運算:
只有兩個布爾值都為 True 時,計算結果才為 True。
True and True # ==> True
True and False # ==> False
False and True # ==> False
False and False # ==> False
- or運算:
只要有一個布爾值為 True,計算結果就是 True。
True or True # ==> True
True or False # ==> True
False or True # ==> True
False or False # ==> False
- not運算:
把True變為False,或者把False變為True:
not True # ==> False
not False # ==> True
布爾運算在計算機中用來做條件判斷,根據計算結果為True或者False,計算機可以自動執行不同的後續代碼。
在Python中,布爾類型還可以與其他數據類型做 and、or和not運算,請看下面的代碼:
a = True
print a and ‘a=T’ or ‘a=F’
計算結果不是布爾類型,而是字串 ‘a=T’,這是為什麼呢?
因為Python把0、空字串''和None看成 False,其他數值和非空字串都看成 True,所以:
>
True and ‘a=T’ 計算結果是 ‘a=T’
繼續計算 ‘a=T’ or ‘a=F’ 計算結果還是 ‘a=T’
要解釋上述結果,又涉及到 and 和 or 運算的一條重要法則:短路計算。
在計算 a and b 時,如果 a 是 False,則根據與運算法則,整個結果必定為 False,因此返回 a;如果 a 是 True,則整個計算結果必定取決與 b,因此返回 b。
在計算 a or b 時,如果 a 是 True,則根據或運算法則,整個計算結果必定為 True,因此返回 a;如果 a 是 False,則整個計算結果必定取決於 b,因此返回 b。
所以Python解釋器在做布爾運算時,只要能提前確定計算結果,它就不會往後算了,直接返回結果。
List和Tuple類型
Pytho建立list
Python內置的一種數據類型是列表:list。 list是一種有序的集合,可以隨時添加和刪除其中的元素。
比如,列出班裡所有同學的名字,就可以用一個list表示:
[‘Michael’, ‘Bob’, ‘Tracy’]
[‘Michael’, ‘Bob’, ‘Tracy’]
list是數學意義上的有序集合,也就是說,list中的元素是按照順序排列的。
構造list非常簡單,按照上面的代碼,直接用[ ]把list的所有元素都括起來,就是一個list對象。通常,我們會把list賦值給一個變量,這樣,就可以通過變量來引用list:
classmates = [‘Michael’, ‘Bob’, ‘Tracy’]
classmates # 列印classmates變量的內容
[‘Michael’, ‘Bob’, ‘Tracy’]
由於Python是動態語言,所以list中包含的元素並不要求都必須是同一種數據類型,我們完全可以在list中包含各種數據:
L = [‘Michael’, 100, True]
一個元素也沒有的list,就是空list:
empty_list = []
Python按照索引訪問list
由於list是一個有序集合,所以,我們可以用一個list按分數從高到低表示出班裡的3個同學:
L = [‘Adam’, ‘Lisa’, ‘Bart’]
那我們如何從list中獲取指定第 N 名的同學呢?方法是通過索引來獲取list中的指定元素。
需要特別注意的是,索引從 0 開始,也就是說,第一個元素的索引是0,第二個元素的索引是1,以此類推。
因此,要列印第一名同學的名字,用 L[0]:
print L[0]
Adam
要列印第二名同學的名字,用 L[1]:
print L[1]
Lisa
要列印第三名同學的名字,用 L[2]:
print L[2]
Bart
要列印第四名同學的名字,用 L[3]:
print L[3]
Traceback (most recent call last):
File ““, line 1, in
IndexError: list index out of range
報錯了! IndexError意思就是索引超出了範圍,因為上面的list只有3個元素,有效的索引是 0,1,2。
所以,使用索引時,千萬注意不要越界。
Python之倒序訪問list
我們還是用一個list按分數從高到低表示出班裡的3個同學:
L = [‘Adam’, ‘Lisa’, ‘Bart’]
這時,老師說,請分數最低的同學站出來。
要寫代碼完成這個任務,我們可以先數一數這個 list,發現它包含3個元素,因此,最後一個元素的索引是2:
print L[2]
Bart
有沒有更簡單的方法?
有!
Bart同學是最後一名,俗稱倒數第一,所以,我們可以用 -1 這個索引來表示最後一個元素:
print L[-1]
Bart
Bart同學表示躺槍。
類似的,倒數第二用 -2 表示,倒數第三用 -3 表示,倒數第四用 -4 表示:
print L[-2]
Lisa
print L[-3]
Adam
print L[-4]
Traceback (most recent call last):
File ““, line 1, in
IndexError: list index out of range
L[-4] 報錯了,因為倒數第四不存在,一共只有3個元素。
使用倒序索引時,也要注意不要越界。
Python之添加新元素
現在,班裡有3名同學:
L = [‘Adam’, ‘Lisa’, ‘Bart’]
今天,班裡轉來一名新同學 Paul,如何把新同學添加到現有的 list 中呢?
第一個辦法是用 list 的 append() 方法,把新同學追加到 list 的末尾:
L = [‘Adam’, ‘Lisa’, ‘Bart’]
L.append(‘Paul’)
print L
[‘Adam’, ‘Lisa’, ‘Bart’, ‘Paul’]
append()總是把新的元素添加到 list 的尾部。
如果 Paul 同學表示自己總是考滿分,要求添加到第一的位置,怎麼辦?
方法是用list的 insert()方法,它接受兩個參數,第一個參數是索引號,第二個參數是待添加的新元素:
L = [‘Adam’, ‘Lisa’, ‘Bart’]
L.insert(0, ‘Paul’)
print L
[‘Paul’, ‘Adam’, ‘Lisa’, ‘Bart’]
L.insert(0, 'Paul') 的意思是,’Paul’將被添加到索引為0 的位置上(也就是第一個),而原來索引為0 的Adam同學,以及後面的所有同學,都自動向後移動一位。
Python從list刪除元素
Paul同學剛來幾天又要轉走了,那麼我們怎麼把Paul 從現有的list中刪除呢?
如果Paul同學排在最後一個,我們可以用list的pop()方法刪除:
L = [‘Adam’, ‘Lisa’, ‘Bart’, ‘Paul’]
L.pop()
‘Paul’
print L
[‘Adam’, ‘Lisa’, ‘Bart’]
pop()方法總是刪掉list的最後一個元素,並且它還返回這個元素,所以我們執行 L.pop() 後,會列印出 ‘Paul’。
如果Paul同學不是排在最後一個怎麼辦?比如Paul同學排在第三:
L = [‘Adam’, ‘Lisa’, ‘Paul’, ‘Bart’]
要把Paul踢出list,我們就必須先定位Paul的位置。由於Paul的索引是2,因此,用 pop(2)把Paul刪掉:
L.pop(2)
‘Paul’
print L
[‘Adam’, ‘Lisa’, ‘Bart’]
Python中替换元素
假設現在班裡仍然是3名同學:
L = [‘Adam’, ‘Lisa’, ‘Bart’]
現在,Bart同學要轉學走了,碰巧來了一個Paul同學,要更新班級成員名單,我們可以先把Bart刪掉,再把Paul添加進來。
另一個辦法是直接用Paul把Bart給替換掉:
L[2] = ‘Paul’
print L
L = [‘Adam’, ‘Lisa’, ‘Paul’]
對list中的某一個索引賦值,就可以直接用新的元素替換掉原來的元素,list包含的元素個數保持不變。
由於Bart還可以用 -1 做索引,因此,下面的代碼也可以完成同樣的替換工作:
L[-1] = ‘Paul’
Python之創建tuple
tuple是另一種有序的列表,中文翻譯為“ 元組 ”。 tuple 和 list 非常類似,但是,tuple一旦創建完畢,就不能修改了。
同樣是表示班裡同學的名稱,用tuple表示如下:
t = (‘Adam’, ‘Lisa’, ‘Bart’)
創建tuple和創建list唯一不同之處是用( )替代了[ ]。
現在,這個t 就不能改變了,tuple沒有 append()方法,也沒有insert()和pop()方法。所以,新同學沒法直接往 tuple 中添加,老同學想退出 tuple 也不行。
獲取 tuple 元素的方式和 list 是一模一樣的,我們可以正常使用 t[0],t[-1]等索引方式訪問元素,但是不能賦值成別的元素,不信可以試試:
t[0] = ‘Paul’
Traceback (most recent call last):
File ““, line 1, in
TypeError: ‘tuple’ object does not support item assignment
Python之創建單元素tuple
tuple和list一樣,可以包含 0 個、1個和任意多個元素。
包含多個元素的 tuple,前面我們已經創建過了。
包含 0 個元素的 tuple,也就是空tuple,直接用 ()表示:
t = ()
print t
()
創建包含1個元素的 tuple 呢?來試試:t = (1)
print t
1
好像哪裡不對! t 不是 tuple ,而是整數1。為什麼呢?
因為()既可以表示tuple,又可以作為括號表示運算時的優先級,結果 (1) 被Python解釋器計算出結果 1,導致我們得到的不是tuple,而是整數 1。
正是因為用()定義單元素的tuple有歧義,所以 Python 規定,單元素 tuple 要多加一個逗號“,”,這樣就避免了歧義:
t = (1,)
print t
(1,)
Python在列印單元素tuple時,也自動添加了一個“,”,為了更明確地告訴你這是一個tuple。
多元素 tuple 加不加這個額外的“,”效果是一樣的:
t = (1, 2, 3,)
print t
(1, 2, 3)
Python之”可變”的tuple
前面我們看到了tuple一旦創建就不能修改。現在,我們來看一個“可變”的tuple:
t = (‘a’, ‘b’, [‘A’, ‘B’])
注意到 t 有 3 個元素:'a','b'和一個list:['A', 'B']。 list作為一個整體是tuple的第3個元素。 list對象可以通過 t[2] 拿到:
L = t[2]
然後,我們把list的兩個元素改一改:
L[0] = ‘X’
L[1] = ‘Y’
再看看tuple的內容:
print t
(‘a’, ‘b’, [‘X’, ‘Y’])
不是說tuple一旦定義後就不可變了嗎?怎麼現在又變了?
別急,我們先看看定義的時候tuple包含的3個元素:
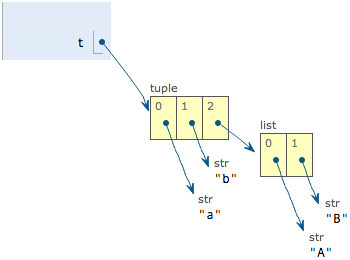
當我們把list的元素'A'和'B'修改為'X'和'Y'後,tuple變為:
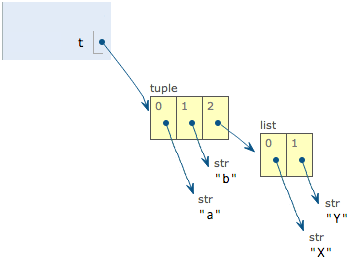
表面上看,tuple的元素確實變了,但其實變的不是 tuple 的元素,而是list的元素。
tuple一開始指向的list並沒有改成別的list,所以,tuple所謂的“不變”是說,tuple的每個元素,指向永遠不變。即指向’a’,就不能改成指向’b’,指向一個list,就不能改成指向其他對象,但指向的這個list本身是可變的!
理解了“指向不變”後,要創建一個內容也不變的tuple怎麼做?那就必須保證tuple的每一個元素本身也不能變。
條件判斷和循環
Python之if語句
計算機之所以能做很多自動化的任務,因為它可以自己做條件判斷。
比如,輸入用戶年齡,根據年齡列印不同的內容,在Python程序中,可以用if語句實現:
age = 20
if age >= 18:
print ‘your age is’, age
print ‘adult’
print ‘END’
注意: Python代碼的縮進規則。具有相同縮進的代碼被視為代碼塊,上面的3,4行 print 語句就構成一個代碼塊(但不包括第5行的print)。如果 if 語句判斷為 True,就會執行這個代碼塊。
縮進請嚴格按照Python的習慣寫法:4個空格,不要使用Tab,更不要混合Tab和空格,否則很容易造成因為縮進引起的語法錯誤。
注意: if 語句後接表達式,然後用:表示代碼塊開始。
age = 20
if age >= 18:
… print ‘your age is’, age
… print ‘adult’
…
your age is 20
adult
Python之 if-else
當if語句判斷表達式的結果為True時,就會執行 if 包含的代碼塊:
if age >= 18
:
print ‘adult’
如果我們想判斷年齡在18歲以下時,印出 ‘teenager’,怎麼辦?
方法是再寫一個 if:
if age < 18:
print ‘teenager’
或者用 not 運算:
if not age >= 18:
print ‘teenager’
細心的同學可以發現,這兩種條件判斷是“非此即彼”的,要么符合條件1,要么符合條件2,因此,完全可以用一個if ... else ... 語句把它們統一起來:
if age >= 18:
print ‘adult’
else:
print ‘teenager’
利用 if … else … 語句,我們可以根據條件表達式的值為 True或者 False,分別執行if代碼塊或者else 代碼塊。
注意: else 後面有個“:”。
Python之 if-elif-else
有的時候,一個 if … else … 還不夠用。比如,根據年齡的劃分:
條件1:18歲或以上:adult
條件2:6歲或以上:teenager
條件3:6歲以下:kid
我們可以用一個 if age >= 18 判斷是否符合條件1,如果不符合,再通過一個 if 判斷 age >= 6 來判斷是否符合條件2,否則,執行條件3:
|
|
這樣寫出來,我們就得到了一個兩層嵌套的 if … else … 語句。這個邏輯沒有問題,但是,如果繼續增加條件,比如3歲以下是 baby:
|
|
這種縮進只會越來越多,代碼也會越來越難看。
要避免嵌套結構的 if … else …,我們可以用 if ... 多個elif ... else ...的結構,一次寫完所有的規則:
|
|
elif 意思就是 else if。這樣一來,我們就寫出了結構非常清晰的一系列條件判斷。
特別注意: 這一系列條件判斷會從上到下依次判斷,如果某個判斷為 True,執行完對應的代碼塊,後面的條件判斷就直接忽略,不再執行了。
- 請思考下面的代碼:
|
|
當 age = 8 時,結果正確,但 age = 20 時,為什麼沒有列印出 adult?
如果要修復,應該如何修復?
Python之 for循環
list或tuple可以表示一個有序集合。如果我們想依次訪問一個list中的每一個元素呢?比如 list:
|
|
如果list只包含幾個元素,這樣寫還行,如果list包含1萬個元素,我們就不可能寫1萬行print。
這時,循環就派上用場了。
Python的 for 循環就可以依次把list或tuple的每個元素迭代出來:
|
|
注意: name 這個變量是在 for 循環中定義的,意思是,依次取出list中的每一個元素,並把元素賦值給 name,然後執行for循環體(就是縮進的代碼塊)。
這樣一來,遍歷一個list或tuple就非常容易了
Python之 while循環
和 for 循環不同的另一種循環是 while 循環,while 循環不會迭代 list 或 tuple 的元素,而是根據表達式判斷循環是否結束。
比如要從 0 開始列印不大於 N 的整數:
|
|
while循環每次先判斷 x < N,如果為True,則執行循環體的代碼塊,否則,退出循環。
在循環體內,x = x + 1 會讓x不斷增加,最終因為x < N不成立而退出循環。
如果沒有這一個語句,while循環在判斷 x < N 時總是為True,就會無限循環下去,變成死循環,所以要特別留意while循環的退出條
Python之 break退出循環
用 for 循環或者 while 循環時,如果要在循環體內直接退出循環,可以使用 break 語句。
比如計算1至100的整數和,我們用while來實現:
|
|
咋一看, while True 就是一個死循環,但是在循環體內,我們還判斷了x > 100 條件成立時,用break語句退出循環,這樣也可以實現循環的結束。
Python之 continue繼續循環
在循環過程中,可以用break退出當前循環,還可以用continue跳過後續循環代碼,繼續下一次循環。
假設我們已經寫好了利用for循環計算平均分的代碼:
|
|
現在老師只想統計及格分數的平均分,就要把x < 60 的分數剔除掉,這時,利用continue,可以做到當x < 60的時候,不繼續執行循環體的後續代碼,直接進入下一次循環:
|
|
Python之 多重循環
在循環內部,還可以嵌套循環,我們來看一個例子:
|
|
x 每循環一次,y 就會循環 3 次,這樣,我們可以列印出一個全排列:
A1
A2
A3
B1
B2
B3
C1
C2
C3
Dict和Set類型
Python之什麼是dict
我們已經知道,list 和 tuple 可以用來表示順序集合,例如,班裡同學的名字:
[‘Adam’, ‘Lisa’, ‘Bart’]
或者考試的成績列表:
[95, 85, 59]
但是,要根據名字找到對應的成績,用兩個 list 表示就不方便。
如果把名字和分數關聯起來,組成類似的查找表:
|
|
給定一個名字,就可以直接查到分數。
Python的 dict 就是專門幹這件事的。用dict表示“名字”-“成績”的查找表如下:
|
|
我們把名字稱為key,對應的成績稱為value,dict就是通過key來查找value。
花括號{}表示這是一個dict,然後按照 key: value, 寫出來即可。最後一個 key: value 的逗號可以省略。
由於dict也是集合,len() 函數可以計算任意集合的大小:
|
|
注意: 一個 key-value 算一個,因此,dict大小為3。
Python之訪問dict
我們已經能創建一個dict,用於表示名字和成績的對應關係:
|
|
那麼,如何根據名字來查找對應的成績呢?
可以簡單地使用 d[key] 的形式來查找對應的 value,這和 list 很像,不同之處是,list 必須使用索引返回對應的元素,而dict使用key:
|
|
注意: 通過 key 訪問 dict 的value,只要 key 存在,dict就返回對應的value。如果key不存在,會直接報錯:KeyError。
要避免 KeyError 發生,有兩個辦法:
一是先判斷一下 key 是否存在,用 in 操作符:
|
|
如果 ‘Paul’ 不存在,if語句判斷為False,自然不會執行 print d[‘Paul’] ,從而避免了錯誤。
二是使用dict本身提供的一個 get 方法,在Key不存在的時候,返回None:
|
|
Python中dict的特點
dict的第一個特點是查找速度快,無論dict有10個元素還是10萬個元素,查找速度都一樣。而list的查找速度隨著元素增加而逐漸下降。
不過dict的查找速度快不是沒有代價的,dict的缺點是佔用內存大,還會浪費很多內容,list正好相反,佔用內存小,但是查找速度慢。
由於dict是按 key 查找,所以,在一個dict中,key不能重複。
dict的第二個特點就是存儲的key-value序對是沒有順序的!這和list不一樣:
|
|
當我們試圖列印這個dict時:
|
|
列印的順序不一定是我們創建時的順序,而且,不同的機器列印的順序都可能不同,這說明dict內部是無序的,不能用dict存儲有序的集合。
dict的第三個特點是作為 key 的元素必須不可變,Python的基本類型如字串、整數、浮點數都是不可變的,都可以作為 key。但是list是可變的,就不能作為 key。
可以試試用list作為key時會報什麼樣的錯誤。
不可變這個限制僅作用於key,value是否可變無所謂:
|
|
最常用的key還是字串,因為用起來最方便。
Python更新dict
dict是可變的,也就是說,我們可以隨時往dict中添加新的 key-value。比如已有dict:
|
|
要把新同學’Paul’的成績 72 加進去,用賦值語句:
|
|
再看看dict的內容:
|
|
如果 key 已經存在,則賦值會用新的 value 替換掉原來的 value:
|
|
Python之 遍歷dict
由於dict也是一個集合,所以,遍歷dict和遍歷list類似,都可以通過 for 循環實現。
直接使用for循環可以遍歷 dict 的 key:
|
|
由於通過 key 可以獲取對應的 value,因此,在循環體內,可以獲取到value的值。
Python中什麼是set
dict的作用是建立一組 key 和一組 value 的映射關係,dict的key是不能重複的。
有的時候,我們只想要 dict 的 key,不關心 key 對應的 value,目的就是保證這個集合的元素不會重複,這時,set就派上用場了。
set 持有一系列元素,這一點和 list 很像,但是set的元素沒有重複,而且是無序的,這點和 dict 的 key很像。
創建 set 的方式是調用 set() 並傳入一個 list,list的元素將作為set的元素:
|
|
可以查看 set 的內容:
|
|
請注意,上述列印的形式類似 list, 但它不是 list,仔細看還可以發現,列印的順序和原始 list 的順序有可能是不同的,因為set內部存儲的元素是無序的。
因為set不能包含重複的元素,所以,當我們傳入包含重複元素的 list 會怎麼樣呢?
結果顯示,set會自動去掉重複的元素,原來的list有4個元素,但set只有3個元素。
Python之 訪問set
由於set存儲的是無序集合,所以我們沒法通過索引來訪問。
訪問 set中的某個元素實際上就是判斷一個元素是否在set中。
例如,存儲了班裡同學名字的set:
我們可以用 in 操作符判斷:
Bart是該班的同學嗎?
Bill是該班的同學嗎?
bart是該班的同學嗎?
看來大小寫很重要,’Bart’ 和 ‘bart’被認為是兩個不同的元素。
Python之 set的特點
set的內部結構和dict很像,唯一區別是不存儲value,因此,判斷一個元素是否在set中速度很快。
set存儲的元素和dict的key類似,必須是不變對象,因此,任何可變對像是不能放入set中的。
最後,set存儲的元素也是沒有順序的。
set的這些特點,可以應用在哪些地方呢?
星期一到星期日可以用字串’MON’, ‘TUE’, … ‘SUN’表示。
假設我們讓用戶輸入星期一至星期日的某天,如何判斷用戶的輸入是否是一個有效的星期呢?
可以用if 語句判斷,但這樣做非常繁瑣:
注意:if 語句中的…表示沒有列出的其它星期名稱,測試時,請輸入完整。
如果事先創建好一個set,包含’MON’ ~ ‘SUN’:
再判斷輸入是否有效,只需要判斷該字串是否在set中:
這樣一來,代碼就簡單多了。
Python之 遍歷set
由於 set 也是一個集合,所以,遍歷 set 和遍歷 list 類似,都可以通過 for 循環實現。
直接使用 for 循環可以遍歷 set 的元素:
注意: 觀察 for 循環在遍歷set時,元素的順序和list的順序很可能是不同的,而且不同的機器上運行的結果也可能不同。
Python之 更新set
由於set存儲的是一組不重複的無序元素,因此,更新set主要做兩件事:
一是把新的元素添加到set中,二是把已有元素從set中刪除。
添加元素時,用set的add()方法:
|
|
如果添加的元素已經存在於set中,add()不會報錯,但是不會加進去了:
|
|
刪除set中的元素時,用set的remove()方法:
|
|
如果刪除的元素不存在set中,remove()會報錯:
|
|
所以用add()可以直接添加,而remove()前需要判斷。
函數
Python之什麼是函數
我們知道圓的面積計算公式為:
S = πr²
當我們知道半徑r的值時,就可以根據公式計算出面積。假設我們需要計算3個不同大小的圓的面積:
r1 = 12.34
r2 = 9.08
r3 = 73.1
s1 = 3.14 r1 r1
s2 = 3.14 r2 r2
s3 = 3.14 r3 r3
當代碼出現有規律的重複的時候,你就需要當心了,每次寫3.14 x x不僅很麻煩,而且,如果要把3.14改成3.14159265359的時候,得全部替換。
有了函數,我們就不再每次寫s = 3.14 x x,而是寫成更有意義的函數調用s = area_of_circle(x),而函數 area_of_circle 本身只需要寫一次,就可以多次調用。
抽像是數學中非常常見的概念。舉個例子:
計算數列的和,比如:1 + 2 + 3 + ... + 100,寫起來十分不方便,於是數學家發明了求和符號∑,可以把1 + 2 + 3 + … + 100記作:
100
∑n
n=1
這種抽象記法非常強大,因為我們看到∑就可以理解成求和,而不是還原成低級的加法運算。
而且,這種抽象記法是可擴展的,比如:
100
∑(n²+1)
n=1
還原成加法運算就變成了:
(1 x 1 + 1) + (2 x 2 + 1) + (3 x 3 + 1) + … + (100 x 100 + 1)
可見,借助抽象,我們才能不關心底層的具體計算過程,而直接在更高的層次上思考問題。
寫計算機程序也是一樣,函數就是最基本的一種代碼抽象的方式。
Python不但能非常靈活地定義函數,而且本身內置了很多有用的函數,可以直接調用。
Python之調用函數
Python內置了很多有用的函數,我們可以直接調用。
要調用一個函數,需要知道函數的名稱和參數,比如求絕對值的函數 abs,它接收一個參數。
可以直接從Python的官方網站查看文檔:
http://docs.python.org/2/library/functions.html#abs
也可以在交互式命令行通過help(abs)查看abs函數的幫助信息。
調用abs函數:
|
|
調用函數的時候,如果傳入的參數數量不對,會報TypeError的錯誤,並且Python會明確地告訴你:abs()有且僅有1個參數,但給出了兩個:
|
|
如果傳入的參數數量是對的,但參數類型不能被函數所接受,也會報TypeError的錯誤,並且給出錯誤信息:str是錯誤的參數類型:
|
|
而比較函數cmp(x, y) 就需要兩個參數,如果x<y,返回-1,如果 x==y,返回 0,如果 x>y,返回 1:
|
|
Python內置的常用函數還包括數據類型轉換函數,比如int()函數可以把其他數據類型轉換為整數:
|
|
str()函數把其他類型轉換成 str:
|
|
Python之編寫函數
在Python中,定義一個函數要使用def語句,依次寫出函數名、括號、括號中的參數和冒號:,然後,在縮進塊中編寫函數體,函數的返回值用 return 語句返回。
我們以自定義一個求絕對值的 my_abs 函數為例:
|
|
請注意,函數體內部的語句在執行時,一旦執行到return時,函數就執行完畢,並將結果返回。因此,函數內部通過條件判斷和循環可以實現非常複雜的邏輯。
如果沒有return語句,函數執行完畢後也會返回結果,只是結果為 None。
return None可以簡寫為return。
Python函數之返回多值
函數可以返回多個值嗎?答案是肯定的。
比如在遊戲中經常需要從一個點移動到另一個點,給出坐標、位移和角度,就可以計算出新的坐標:
# math包提供了sin()和 cos()函數,我們先用import引用它:
|
|
這樣我們就可以同時獲得返回值:
|
|
但其實這只是一種假象,Python函數返回的仍然是單一值:
|
|
用print列印返回結果,原來返回值是一個tuple!
但是,在語法上,返回一個tuple可以省略括號,而多個變量可以同時接收一個tuple,按位置賦給對應的值,所以,Python的函數返回多值其實就是返回一個tuple,但寫起來更方便。
Python之遞歸函數
在函數內部,可以調用其他函數。如果一個函數在內部調用自身本身,這個函數就是遞歸函數。
舉個例子,我們來計算階乘n! = 1 * 2 * 3 * ... * n,用函數 fact(n)表示,可以看出:
|
|
所以,fact(n)可以表示為n * fact(n-1),只有n=1時需要特殊處理。
於是,fact(n)用遞歸的方式寫出來就是:
|
|
上面就是一個遞歸函數。可以試試:
|
|
如果我們計算fact(5),可以根據函數定義看到計算過程如下:
|
|
遞歸函數的優點是定義簡單,邏輯清晰。理論上,所有的遞歸函數都可以寫成循環的方式,但循環的邏輯不如遞歸清晰。
使用遞歸函數需要注意防止棧溢出。在計算機中,函數調用是通過棧(stack)這種數據結構實現的,每當進入一個函數調用,棧就會加一層棧幀,每當函數返回,棧就會減一層棧幀。由於棧的大小不是無限的,所以,遞歸調用的次數過多,會導致棧溢出。可以試試計算 fact(10000)。
Python之定義默認參數
定義函數的時候,還可以有默認參數。
例如Python自帶的int()函數,其實就有兩個參數,我們既可以傳一個參數,又可以傳兩個參數:
int()函數的第二個參數是轉換進制,如果不傳,默認是十進制 (base=10),如果傳了,就用傳入的參數。
可見,函數的默認參數的作用是簡化調用,你只需要把必須的參數傳進去。但是在需要的時候,又可以傳入額外的參數來覆蓋默認參數值。
我們來定義一個計算 x 的N次方的函數:
假設計算平方的次數最多,我們就可以把 n 的默認值設定為 2:
這樣一來,計算平方就不需要傳入兩個參數了:
由於函數的參數按從左到右的順序匹配,所以默認參數只能定義在必需參數的後面:
Python之定義可變參數
如果想讓一個函數能接受任意個參數,我們就可以定義一個可變參數:
|
|
可變參數的名字前面有個 *號,我們可以傳入0個、1個或多個參數給可變參數:
可變參數也不是很神秘,Python解釋器會把傳入的一組參數組裝成一個tuple傳遞給可變參數,因此,在函數內部,直接把變量 args 看成一個tuple就好了。
定義可變參數的目的也是為了簡化調用。假設我們要計算任意個數的平均值,就可以定義一個可變參數:
這樣,在調用的時候,可以這樣寫:
切割
對list進行切割
取一個list的部分元素是非常常見的操作。比如,一個list如下:
|
|
取前3個元素,應該怎麼做?
笨辦法:
之所以是笨辦法是因為擴展一下,取前N個元素就沒轍了。
取前N個元素,也就是索引為0-(N-1)的元素,可以用循環:
對這種經常取指定索引範圍的操作,用循環十分繁瑣,因此,Python提供了切片(Slice)操作符,能大大簡化這種操作。
對應上面的問題,取前3個元素,用一行代碼就可以完成切片:
|
|
L[0:3]表示,從索引0開始取,直到索引3為止,但不包括索引3。即索引0,1,2,正好是3個元素。
如果第一個索引是0,還可以省略:
|
|
也可以從索引1開始,取出2個元素出來:
|
|
只用一個 : ,表示從頭到尾:
|
|
因此,L[:]實際上複製出了一個新list。
切片操作還可以指定第三個參數:
|
|
第三個參數表示每N個取一個,上面的 L[::2] 會每兩個元素取出一個來,也就是隔一個取一個。
把list換成tuple,切片操作完全相同,只是切片的結果也變成了tuple。
倒序切割
對於list,既然Python支持L[-1]取倒數第一個元素,那麼它同樣支持倒數切片,試試:
|
|
記住倒數第一個元素的索引是-1。倒序切片包含起始索引,不包含結束索引。
對字串切割
字串 ‘xxx’和 Unicode字串 u’xxx’也可以看成是一種list,每個元素就是一個字符。因此,字串也可以用切片操作,只是操作結果仍是字串:
|
|
在很多編程語言中,針對字串提供了很多各種截取函數,其實目的就是對字串切片。 Python沒有針對字串的截取函數,只需要切片一個操作就可以完成,非常簡單。
任務
字串有個方法 upper() 可以把字符變成大寫字母:
但它會把所有字母都變成大寫。請設計一個函數,它接受一個字串,然後返回一個僅首字母變成大寫的字串。
提示:利用切片操作簡化字串操作。
迭代
什麼是迭代
在Python中,如果給定一個list或tuple,我們可以通過for循環來遍歷這個list或tuple,這種遍歷我們成為迭代(Iteration)。
在Python中,迭代是通過 for ... in 來完成的,而很多語言比如C或者Java,迭代list是通過下標完成的,比如Java代碼:
|
|
可以看出,Python的for循環抽象程度要高於Java的for循環。
因為 Python 的 for循環不僅可以用在list或tuple上,還可以作用在其他任何可迭代對像上。
因此,迭代操作就是對於一個集合,無論該集合是有序還是無序,我們用 for 循環總是可以依次取出集合的每一個元素。
>
注意: 集合是指包含一組元素的數據結構,我們已經介紹的包括:
- 有序集合:list,tuple,str和unicode;
- 無序集合:set
- 無序集合併且具有 key-value 對:dict
而迭代是一個動詞,它指的是一種操作,在Python中,就是 for 循環。
迭代與按下標訪問數組最大的不同是,後者是一種具體的迭代實現方式,而前者只關心迭代結果,根本不關心迭代內部是如何實現的。
索引迭代
Python中,迭代永遠是取出元素本身,而非元素的索引。
對於有序集合,元素確實是有索引的。有的時候,我們確實想在 for 循環中拿到索引,怎麼辦?
方法是使用enumerate() 函數:
|
|
變成了類似:
因此,迭代的每一個元素實際上是一個tuple:
如果我們知道每個tuple元素都包含兩個元素,for循環又可以進一步簡寫為:
這樣不但代碼更簡單,而且還少了兩條賦值語句。
可見,索引迭代也不是真的按索引訪問,而是由 enumerate() 函數自動把每個元素變成 (index, element) 這樣的tuple,再迭代,就同時獲得了索引和元素本身。
迭代dict的value
我們已經了解了dict對象本身就是可迭代對象,用 for 循環直接迭代 dict,可以每次拿到dict的一個key。
如果我們希望迭代 dict 對象的value,應該怎麼做?
dict 對像有一個 values() 方法,這個方法把dict轉換成一個包含所有value的list,這樣,我們迭代的就是 dict的每一個 value:
|
|
如果仔細閱讀Python的文檔,還可以發現,dict除了values()方法外,還有一個 itervalues() 方法,用 itervalues()方法替代 values() 方法,迭代效果完全一樣:
|
|
那這兩個方法有何不同之處呢?
values()方法實際上把一個 dict 轉換成了包含 value 的list。但是
itervalues()方法不會轉換,它會在迭代過程中依次從 dict 中取出 value,所以 itervalues() 方法比 values() 方法節省了生成 list 所需的內存。列印itervalues() 發現它返回一個
對象,這說明在Python中, for 循環可作用的迭代對象遠不止list,tuple,str,unicode,dict等,任何可迭代對像都可以作用於for循環,而內部如何迭代我們通常並不用關心。
如果一個對像說自己可迭代,那我們就直接用 for 循環去迭代它,可見,迭代是一種抽象的數據操作,它不對迭代對象內部的數據有任何要求。
迭代dict的key和value
我們了解瞭如何迭代 dict 的key和value,那麼,在一個 for 循環中,能否同時迭代 key和value?答案是肯定的。
首先,我們看看 dict 對象的 items() 方法返回的值:
|
|
可以看到,items() 方法把dict對象轉換成了包含tuple的list,我們對這個list進行迭代,可以同時獲得key和value:
|
|
和values() 有一個itervalues() 類似,items() 也有一個對應的iteritems(),iteritems() 不把dict轉換成list,而是在迭代過程中不斷給出tuple,所以, iteritems() 不佔用額外的內存。
列表生成式
生成列表
要生成list [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],我們可以用range(1, 11):
|
|
但如果要生成[1x1, 2x2, 3x3, …, 10x10]怎麼做?方法一是循環:
但是循環太繁瑣,而列表生成式則可以用一行語句代替循環生成上面的list:
這種寫法就是Python特有的列表生成式。利用列表生成式,可以以非常簡潔的代碼生成 list。
寫列表生成式時,把要生成的元素 x * x 放到前面,後面跟 for 循環,就可以把list創建出來,十分有用,多寫幾次,很快就可以熟悉這種語法。
複雜表達式
使用for循環的迭代不僅可以迭代普通的list,還可以迭代dict。
假設有如下的dict:
|
|
完全可以通過一個複雜的列表生成式把它變成一個 HTML 表格:
|
|
注:字串可以通過 % 進行格式化,用指定的參數替代 %s。字串的join()方法可以把一個 list 拼接成一個字串。
把列印出來的結果保存為一個html文件,就可以在瀏覽器中看到效果了:
|
|

條件過濾
列表生成式的 for 循環後面還可以加上 if 判斷。例如:
|
|
如果我們只想要偶數的平方,不改動 range()的情況下,可以加上 if 來篩選:
有了 if 條件,只有 if 判斷為 True 的時候,才把循環的當前元素添加到列表中。
多層表達式
for循環可以嵌套,因此,在列表生成式中,也可以用多層for循環來生成列表。
對於字串 ‘ABC’ 和 ‘123’,可以使用兩層循環,生成全排列:
|
|
翻譯成循環代碼就像下面這樣:
python 進階
函數式編譯
python把函數作為參數
前面我們講了高階函數的概念,並編寫了一個簡單的高階函數:
如果傳入abs作為參數f的值:
根據函數的定義,函數執行的程式碼實際上是:
由於參數 x, y 和 f 都可以任意傳入,如果 f 傳入其他函數,就可以得到不同的返回值。
python中map()函數
map()是 Python 內置的高階函數,它接收一個函數 f 和一個 list,並通過把函數 f依次作用在list的每個元素上,得到一個新的 list 並返回。
例如,對於list [1, 2, 3, 4, 5, 6, 7, 8, 9]
如果希望把list的每個元素都作平方,就可以用map()函數:
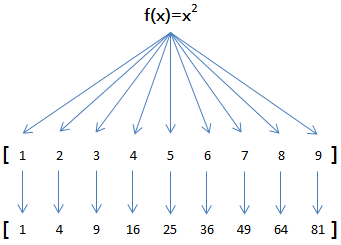
因此,我們只需要傳入函數f(x)=x*x,就可以利用map()函數完成這個計算:
輸出結果:
注意:map()函數不改變原有的 list,而是返回一個新的 list。
利用map()函數,可以把一個 list 轉換為另一個 list,只需要傳入轉換函數。
由於list包含的元素可以是任何類型,因此,map() 不僅僅可以處理只包含數值的 list,事實上它可以處理包含任意類型的 list,只要傳入的函數f可以處理這種數據類型。
python中reduce()函數
reduce()函數也是Python內置的一個高階函數。 reduce()函數接收的參數和map()類似,一個函數f,一個list,但行為和map()不同,reduce()傳入的函數f 必須接收兩個參數,reduce()對list的每個元素反複調用函數f,並返回最終結果值。
例如,編寫一個f函數,接收x和y,返回x和y的和:
調用 reduce(f, [1, 3, 5, 7, 9])時,reduce函數將做如下計算:
>
先計算頭兩個元素:f(1, 3),結果為4;
再把結果和第3個元素計算:f(4, 5),結果為9;
再把結果和第4個元素計算:f(9, 7),結果為16;
再把結果和第5個元素計算:f(16, 9),結果為25;
由於沒有更多的元素了,計算結束,返回結果25。
上述計算實際上是對 list 的所有元素求和。雖然Python內置了求和函數sum(),但是,利用reduce()求和也很簡單。
reduce()還可以接收第3個可選參數,作為計算的初始值。如果把初始值設為100,計算:
結果將變為125,因為第一輪計算是:
計算初始值和第一個元素:f(100, 1),結果為101。
python中filter()函數
filter()函數是Python 內置的另一個有用的高階函數,filter()函數接收一個函數f和一個list,這個函數f 的作用是對每個元素進行判斷,返回True或False,filter()根據判斷結果自動過濾掉不符合條件的元素,返回由符合條件元素組成的新list。
例如,要從一個list [1, 4, 6, 7, 9, 12, 17]中刪除偶數,保留奇數,首先,要編寫一個判斷奇數的函數:
|
|
然後,利用filter()過濾掉偶數:
|
|
結果:[1, 7, 9, 17]
利用filter(),可以完成很多有用的功能,例如,刪除 None 或者空字符串:
|
|
結果:[‘test’, ‘str’, ‘END’]
注意: s.strip(rm) 刪除 s 字符串中開頭、結尾處的 rm 序列的字符。
當rm為空時,默認刪除空白符(包括’\n’, ‘\r’, ‘\t’, ‘ ‘),如下:
|
|
結果: ‘123’
|
|
結果:’123’
python中自定義排序函數
Python內置的 sorted()函數可對list進行排序:
|
|
但sorted()也是一個高階函數,它可以接收一個比較函數來實現自定義排序,比較函數的定義是,傳入兩個待比較的元素x, y,如果x 應該排在y 的前面,返回-1,如果x 應該排在y 的後面,返回1。如果 x 和 y 相等,返回 0。
因此,如果我們要實現倒序排序,只需要編寫一個reversed_cmp函數:
|
|
這樣,調用 sorted() 並傳入 reversed_cmp 就可以實現倒序排序:
|
|
sorted()也可以對字符串進行排序,字符串默認按照ASCII大小來比較:
|
|
‘Zoo’排在’about’之前是因為’Z’的ASCII碼比’a’小。
python中返回函數
Python的函數不但可以返回int、str、list、dict等數據類型,還可以返回函數!
例如,定義一個函數 f(),我們讓它返回一個函數 g,可以這樣寫:
|
|
仔細觀察上面的函數定義,我們在函數 f 內部又定義了一個函數 g。由於函數 g 也是一個對象,函數名 g 就是指向函數 g 的變量,所以,最外層函數 f 可以返回變量 g,也就是函數 g 本身。
調用函數 f,我們會得到 f 返回的一個函數:
|
|
請注意區分返回函數和返回值:
|
|
返回函數可以把一些計算延遲執行。例如,如果定義一個普通的求和函數:
|
|
調用calc_sum()函數時,將立刻計算並得到結果:
|
|
但是,如果返回一個函數,就可以“延遲計算”:
|
|
調用calc_sum()並沒有計算出結果,而是返回函數:
|
|
對返回的函數進行調用時,才計算出結果:
|
|
由於可以返回函數,我們在後續代碼裡就可以決定到底要不要調用該函數。
python中閉包
在函數內部定義的函數和外部定義的函數是一樣的,只是他們無法被外部訪問:
|
|
將 g 的定義移入函數 f 內部,防止其他代碼調用 g:
|
|
但是,考察上一小節定義的 calc_sum 函數:
|
|
注意: 發現沒法把 lazy_sum 移到 calc_sum 的外部,因為它引用了 calc_sum 的參數 lst。
像這種內層函數引用了外層函數的變量(參數也算變量),然後返回內層函數的情況,稱為閉包(Closure)。
閉包的特點是返回的函數還引用了外層函數的局部變量,所以,要正確使用閉包,就要確保引用的局部變量在函數返回後不能變。舉例如下:
|
|
你可能認為調用f1(),f2()和f3()結果應該是1,4,9,但實際結果全部都是 9(請自己動手驗證)。
原因就是當count()函數返回了3個函數時,這3個函數所引用的變量 i 的值已經變成了3。由於f1、f2、f3並沒有被調用,所以,此時他們並未計算 i*i,當 f1 被調用時:
|
|
因此,返回函數不要引用任何循環變量,或者後續會發生變化的變量。
python中匿名函數
高階函數可以接收函數做參數,有些時候,我們不需要顯式地定義函數,直接傳入匿名函數更方便。
在Python中,對匿名函數提供了有限支持。還是以map()函數為例,計算 f(x)=x2 時,除了定義一個f(x)的函數外,還可以直接傳入匿名函數:
|
|
通過對比可以看出,匿名函數 lambda x: x * x 實際上就是:
關鍵字lambda 表示匿名函數,冒號前面的 x 表示函數參數。
匿名函數有個限制,就是只能有一個表達式,不寫return,返回值就是該表達式的結果。
使用匿名函數,可以不必定義函數名,直接創建一個函數對象,很多時候可以簡化代碼:
|
|
返回函數的時候,也可以返回匿名函數:
|
|
python中編寫無參數decorator
Python的 decorator本質上就是一個高階函數,它接收一個函數作為參數,然後,返回一個新函數。
使用 decorator 用Python提供的@語法,這樣可以避免手動編寫f = decorate(f)這樣的代碼。
考察一個@log的定義:
|
|
對於階乘函數,@log工作得很好:
|
|
結果:
|
|
但是,對於參數不是一個的函數,調用將報錯:
|
|
結果:
|
|
因為add()函數需要傳入兩個參數,但是@log寫死了只含一個參數的返回函數。
要讓@log自適應任何參數定義的函數,可以利用Python的*args和**kw,保證任意個數的參數總是能正常調用:
|
|
現在,對於任意函數,@log 都能正常工作。
python中編寫帶參數decorator
考察上一節的@log裝飾器:
|
|
發現對於被裝飾的函數,log打印的語句是不能變的(除了函數名)。
如果有的函數非常重要,希望打印出’[INFO] call xxx()…’,有的函數不太重要,希望打印出’[DEBUG] call xxx()…’,這時,log函數本身就需要傳入’INFO’或’DEBUG’這樣的參數,類似這樣:
|
|
把上面的定義翻譯成高階函數的調用,就是:
|
|
上面的語句看上去還是比較繞,再展開一下:
|
|
上面的語句又相當於:
|
|
所以,帶參數的log函數首先返回一個decorator函數,再讓這個decorator函數接收my_func並返回新函數:
|
|
執行結果:
|
|
對於這種3層嵌套的decorator定義,你可以先把它拆開:
|
|
拆開以後會發現,調用會失敗,因為在3層嵌套的decorator定義中,最內層的wrapper引用了最外層的參數prefix,所以,把一個閉包拆成普通的函數調用會比較困難。不支持閉包的編程語言要實現同樣的功能就需要更多的代碼。
python中完善decorator
@decorator可以動態實現函數功能的增加,但是,經過@decorator“改造”後的函數,和原函數相比,除了功能多一點外,有沒有其它不同的地方?
在沒有decorator的情況下,打印函數名:
|
|
輸出: f1
有decorator的情況下,再打印函數名:
|
|
輸出: wrapper
可見,由於decorator返回的新函數函數名已經不是'f2',而是@log內部定義的'wrapper'。這對於那些依賴函數名的代碼就會失效。 decorator還改變了函數的__doc__等其它屬性。如果要讓調用者看不出一個函數經過了@decorator的“改造”,就需要把原函數的一些屬性複製到新函數中:
|
|
這樣寫decorator很不方便,因為我們也很難把原函數的所有必要屬性都一個一個複製到新函數上,所以Python內置的functools可以用來自動化完成這個“複製”的任務:
|
|
最後需要指出,由於我們把原函數簽名改成了(*args, **kw),因此,無法獲得原函數的原始參數信息。即便我們採用固定參數來裝飾只有一個參數的函數:
|
|
也可能改變原函數的參數名,因為新函數的參數名始終是 'x',原函數定義的參數名不一定叫 'x'。
python中偏函數
當一個函數有很多參數時,調用者就需要提供多個參數。如果減少參數個數,就可以簡化調用者的負擔。
比如,int()函數可以把字符串轉換為整數,當僅傳入字符串時,int()函數默認按十進制轉換:
|
|
但int()函數還提供額外的base參數,默認值為10。如果傳入base參數,就可以做N進制的轉換:
|
|
假設要轉換大量的二進製字符串,每次都傳入int(x, base=2)非常麻煩,於是,我們想到,可以定義一個int2()的函數,默認把base=2傳進去:
|
|
這樣,我們轉換二進制就非常方便了:
|
|
functools.partial就是幫助我們創建一個偏函數的,不需要我們自己定義int2(),可以直接使用下面的代碼創建一個新的函數int2:
|
|
所以,functools.partial可以把一個參數多的函數變成一個參數少的新函數,少的參數需要在創建時指定默認值,這樣,新函數調用的難度就降低了。
模塊
python之導入模塊
要使用一個模塊,我們必須首先導入該模塊。 Python使用import語句導入一個模塊。例如,導入系統自帶的模塊math:
|
|
你可以認為math就是一個指向已導入模塊的變量,通過該變量,我們可以訪問math模塊中所定義的所有公開的函數、變量和類:
|
|
如果我們只希望導入用到的math模塊的某幾個函數,而不是所有函數,可以用下面的語句:
|
|
這樣,可以直接引用 pow, sin, log 這3個函數,但math的其他函數沒有導入進來:
|
|
如果遇到名字衝突怎麼辦?比如math模塊有一個log函數,logging模塊也有一個log函數,如果同時使用,如何解決名字衝突?
如果使用import導入模塊名,由於必須通過模塊名引用函數名,因此不存在衝突:
|
|
如果使用from...import導入log函數,勢必引起衝突。這時,可以給函數起個“別名”來避免衝突:
|
|
python中動態導入模塊
如果導入的模塊不存在,Python解釋器會報ImportError錯誤:
|
|
有的時候,兩個不同的模塊提供了相同的功能,比如 StringIO 和cStringIO都提供了StringIO這個功能。
這是因為Python是動態語言,解釋執行,因此Python代碼運行速度慢。
如果要提高Python代碼的運行速度,最簡單的方法是把某些關鍵函數用C語言重寫,這樣就能大大提高執行速度。
同樣的功能,StringIO是純Python代碼編寫的,而cStringIO部分函數是 C寫的,因此 cStringIO 運行速度更快。
利用ImportError錯誤,我們經常在Python中動態導入模塊:
|
|
上述代碼先嘗試從cStringIO導入,如果失敗了(比如cStringIO沒有被安裝),再嘗試從StringIO導入。這樣,如果cStringIO模塊存在,則我們將獲得更快的運行速度,如果cStringIO不存在,則頂多代碼運行速度會變慢,但不會影響代碼的正常執行。
try 的作用是捕獲錯誤,並在捕獲到指定錯誤時執行 except 語句。
python之使用future
Python的新版本會引入新的功能,但是,實際上這些功能在上一個老版本中就已經存在了。要“試用”某一新的特性,就可以通過導入__future__模塊的某些功能來實現。
例如,Python 2.7的整數除法運算結果仍是整數:
|
|
但是,Python 3.x已經改進了整數的除法運算,“/”除將得到浮點數,“//”除才仍是整數:
|
|
要在Python 2.7中引入3.x的除法規則,導入__future__的division:
|
|
當新版本的一個特性與舊版本不兼容時,該特性將會在舊版本中添加到``future``中,以便舊的代碼能在舊版本中測試新特性。
python之安裝第三方模塊
物件導向編程基礎
python之定義類並創建實例
在Python中,類通過class關鍵字定義。以Person為例,定義一個Person類如下:
|
|
按照 Python 的編程習慣,類名以大寫字母開頭,緊接著是(object),表示該類是從哪個類繼承下來的。類的繼承將在後面的章節講解,現在我們只需要簡單地從object類繼承。
有了Person類的定義,就可以創建出具體的xiaoming、xiaohong等實例。創建實例使用 類名+(),類似函數調用的形式創建:
|
|
python中創建實例屬性
雖然可以通過Person類創建出xiaoming、xiaohong等實例,但是這些實例看上除了地址不同外,沒有什麼其他不同。在現實世界中,區分xiaoming、xiaohong要依靠他們各自的名字、性別、生日等屬性。
如何讓每個實例擁有各自不同的屬性?由於Python是動態語言,對每一個實例,都可以直接給他們的屬性賦值,例如,給xiaoming這個實例加上name、gender和birth屬性:
|
|
給xiaohong加上的屬性不一定要和xiaoming相同:
|
|
實例的屬性可以像普通變量一樣進行操作:
|
|
python中初始化實例屬性
雖然我們可以自由地給一個實例綁定各種屬性,但是,現實世界中,一種類型的實例應該擁有相同名字的屬性。例如,Person類應該在創建的時候就擁有name、gender和 birth屬性,怎麼辦?
在定義 Person 類時,可以為Person類添加一個特殊的__init__()方法,當創建實例時,__init__()方法被自動調用,我們就能在此為每個實例都統一加上以下屬性:
|
|
__init__() 方法的第一個參數必須是self(也可以用別的名字,但建議使用習慣用法),後續參數則可以自由指定,和定義函數沒有任何區別。
相應地,創建實例時,就必須要提供除self以外的參數:
|
|
有了__init__()方法,每個Person實例在創建時,都會有 name、gender 和birth這3個屬性,並且,被賦予不同的屬性值,訪問屬性使用.操作符:
|
|
要特別注意的是,初學者定義__init__()方法常常忘記了 self參數:
|
|
這會導致創建失敗或運行不正常,因為第一個參數name被Python解釋器傳入了實例的引用,從而導致整個方法的調用參數位置全部沒有對上。
python中訪問限制
我們可以給一個實例綁定很多屬性,如果有些屬性不希望被外部訪問到怎麼辦?
Python對屬性權限的控制是通過屬性名來實現的,如果一個屬性由雙下底線開頭(__),該屬性就無法被外部訪問。看例子:
|
|
可見,只有以雙下底線開頭的”__job“不能直接被外部訪問。
但是,如果一個屬性以”__xxx__“的形式定義,那它又可以被外部訪問了,以”__xxx__“定義的屬性在Python的類中被稱為特殊屬性,有很多預定義的特殊屬性可以使用,通常我們不要把普通屬性用”__xxx__“定義。
以單下底線開頭的屬性”_xxx“雖然也可以被外部訪問,但是,按照習慣,他們不應該被外部訪問。
python中創建類屬性
類是模板,而實例則是根據類創建的對象。
綁定在一個實例上的屬性不會影響其他實例,但是,類本身也是一個對象,如果在類上綁定一個屬性,則所有實例都可以訪問類的屬性,並且,所有實例訪問的類屬性都是同一個!也就是說,實例屬性每個實例各自擁有,互相獨立,而類屬性有且只有一份。
定義類屬性可以直接在class中定義:
|
|
因為類屬性是直接綁定在類上的,所以,訪問類屬性不需要創建實例,就可以直接訪問:
|
|
對一個實例調用類的屬性也是可以訪問的,所有實例都可以訪問到它所屬的類的屬性:
|
|
由於Python是動態語言,類屬性也是可以動態添加和修改的:
|
|
因為類屬性只有一份,所以,當Person類的address改變時,所有實例訪問到的類屬性都改變了。
python中類屬性和實例屬性名字衝突怎麼辦
修改類屬性會導致所有實例訪問到的類屬性全部都受影響,但是,如果在實例變量上修改類屬性會發生什麼問題呢?
|
|
結果如下:
|
|
我們發現,在設置了p1.address = 'China'後,p1訪問 address 確實變成了 ‘China’,但是,Person.address和p2.address仍然是’Earch’,怎麼回事?
原因是p1.address = 'China'並沒有改變Person 的address,而是給p1這個實例綁定了實例屬性address ,對p1來說,它有一個實例屬性address(值是’China’),而它所屬的類Person也有一個類屬性address,所以:
訪問 p1.address 時,優先查找實例屬性,返回’China’。
訪問 p2.address 時,p2沒有實例屬性address,但是有類屬性address,因此返回’Earth’。
可見,當實例屬性和類屬性重名時,實例屬性優先級高,它將屏蔽掉對類屬性的訪問。
當我們把 p1 的 address 實例屬性刪除後,訪問 p1.address 就又返回類屬性的值 ‘Earth’了:
|
|
可見,千萬不要在實例上修改類屬性,它實際上並沒有修改類屬性,而是給實例綁定了一個實例屬性。
python中定義實例方法
一個實例的私有屬性就是以__開頭的屬性,無法被外部訪問,那這些屬性定義有什麼用?
雖然私有屬性無法從外部訪問,但是,從類的內部是可以訪問的。除了可以定義實例的屬性外,還可以定義實例的方法。
實例的方法就是在類中定義的函數,它的第一個參數永遠是self,指向調用該方法的實例本身,其他參數和一個普通函數是完全一樣的:
|
|
get_name(self)就是一個實例方法,它的第一個參數是self。__init__(self, name)其實也可看做是一個特殊的實例方法。
調用實例方法必須在實例上調用:
|
|
在實例方法內部,可以訪問所有實例屬性,這樣,如果外部需要訪問私有屬性,可以通過方法調用獲得,這種數據封裝的形式除了能保護內部數據一致性外,還可以簡化外部調用的難度。
python中方法也是屬性
我們在class中定義的實例方法其實也是屬性,它實際上是一個函數對象:
|
|
也就是說,p1.get_grade返回的是一個函數對象,但這個函數是一個綁定到實例的函數,p1.get_grade() 才是方法調用。
因為方法也是一個屬性,所以,它也可以動態地添加到實例上,只是需要用 types.MethodType()把一個函數變為一個方法:
|
|
給一個實例動態添加方法並不常見,直接在class中定義要更直觀。
python中定義類方法
和屬性類似,方法也分實例方法和類方法。
在class中定義的全部是實例方法,實例方法第一個參數self是實例本身。
要在class中定義類方法,需要這麼寫:
|
|
通過標記一個 @classmethod,該方法將綁定到Person類上,而非類的實例。類方法的第一個參數將傳入類本身,通常將參數名命名為cls,上面的 cls.count實際上相當於Person.count。
因為是在類上調用,而非實例上調用,因此類方法無法獲得任何實例變量,只能獲得類的引用。
類的繼承
python中繼承一個類
如果已經定義了Person類,需要定義新的Student和Teacher類時,可以直接從Person類繼承:
|
|
定義Student類時,只需要把額外的屬性加上,例如score:
|
|
一定要用super(Student, self).__init__(name, gender)去初始化父類,否則,繼承自Person 的 Student將沒有name和gender。
函數super(Student, self)將返回當前類繼承的父類,即Person ,然後調用__init__()方法,注意self參數已在super()中傳入,在__init__()中將隱式傳遞,不需要寫出(也不能寫)。
python中判斷類型
函數isinstance()可以判斷一個變量的類型,既可以用在Python內置的數據類型如str、list、dict,也可以用在我們自定義的類,它們本質上都是數據類型。
假設有如下的Person、Student和Teacher 的定義及繼承關係如下:
|
|
當我們拿到變量 p、s、t 時,可以使用 isinstance判斷類型:
|
|
這說明在繼承鏈上,一個父類的實例不能是子類類型,因為子類比父類多了一些屬性和方法。
我們再考察s :
|
|
s 是Student類型,不是Teacher類型,這很容易理解。但是,s 也是Person類型,因為Student繼承自Person,雖然它比Person多了一些屬性和方法,但是,把s看成Person的實例也是可以的。
這說明在一條繼承鏈上,一個實例可以看成它本身的類型,也可以看成它父類的類型。
python中多態
類具有繼承關係,並且子類類型可以向上轉型看做父類類型,如果我們從 Person派生出 Student和Teacher,並都寫了一個 whoAmI() 方法:
|
|
在一個函數中,如果我們接收一個變量x,則無論該x是Person、Student還是Teacher,都可以正確打印出結果:
|
|
運行結果:
這種行為稱為多態。也就是說,方法調用將作用在x 的實際類型上。s 是Student類型,它實際上擁有自己的whoAmI()方法以及從Person繼承的whoAmI方法,但調用s.whoAmI()總是先查找它自身的定義,如果沒有定義,則順著繼承鏈向上查找,直到在某個父類中找到為止。
由於Python是動態語言,所以,傳遞給函數who_am_i(x)的參數 x 不一定是 Person 或 Person 的子類型。任何數據類型的實例都可以,只要它有一個whoAmI()的方法即可:
|
|
這是動態語言和靜態語言(例如Java)最大的差別之一。動態語言調用實例方法,不檢查類型,只要方法存在,參數正確,就可以調用。
python中多重繼承
除了從一個父類繼承外,Python允許從多個父類繼承,稱為多重繼承。
多重繼承的繼承鏈就不是一棵樹了,它像這樣:
|
|
看下圖:
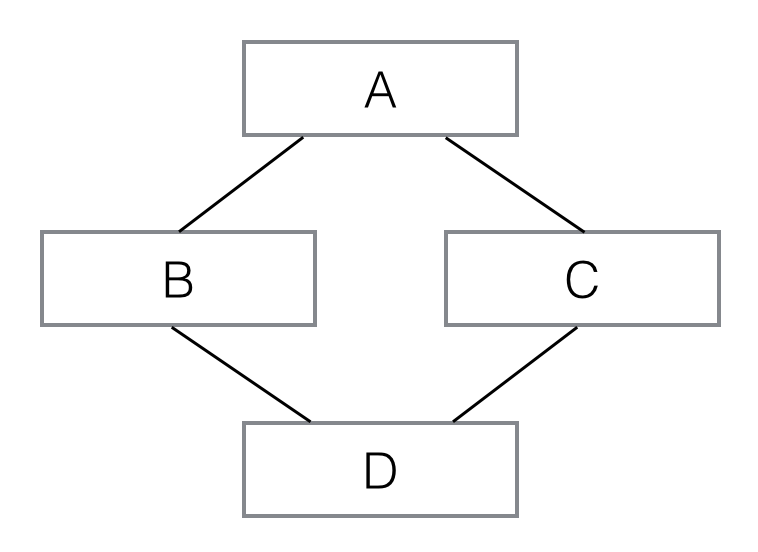
像這樣,D同時繼承自 B和C,也就是D擁有了A、B、C的全部功能。多重繼承通過super()調用__init__()方法時,A雖然被繼承了兩次,但__init__()只調用一次:
|
|
多重繼承的目的是從兩種繼承樹中分別選擇並繼承出子類,以便組合功能使用。
舉個例子,Python的網絡服務器有TCPServer、UDPServer、UnixStreamServer、UnixDatagramServer,而服務器運行模式有 多進程ForkingMixin和多線程ThreadingMixin兩種。
要創建多進程模式的TCPServer:
|
|
要創建多線程模式的 UDPServer:
|
|
如果沒有多重繼承,要實現上述所有可能的組合需要 4x2=8 個子類。
python中獲取對象信息
拿到一個變量,除了用 isinstance()判斷它是否是某種類型的實例外,還有沒有別的方法獲取到更多的信息呢?
例如,已有定義:
|
|
首先可以用type()函數獲取變量的類型,它返回一個Type對象:
|
|
其次,可以用dir()函數獲取變量的所有屬性:
|
|
對於實例變量,dir()返回所有實例屬性,包括__class__這類有特殊意義的屬性。注意到方法whoAmI也是s的一個屬性。
如何去掉__xxx__這類的特殊屬性,只保留我們自己定義的屬性?回顧一下filter()函數的用法。
dir()返回的屬性是字符串列表,如果已知一個屬性名稱,要獲取或者設置對象的屬性,就需要用getattr()和setattr( )函數了:
|
|
定製類
一部分特殊方法

python中str和repr
如果要把一個類的實例變成str,就需要實現特殊方法__str__():
|
|
現在,在交互式命令行下用print試試:
|
|
但是,如果直接敲變量p:
|
|
似乎__str__() 不會被調用。
因為 Python 定義了__str__()和__repr__()兩種方法,__str__()用於顯示給用戶,而__repr__()用於顯示給開發人員。
有一個偷懶的定義__repr__的方法:
|
|
python中cmp
對int、str 等內置數據類型排序時,Python的sorted() 按照默認的比較函數cmp排序,但是,如果對一組Student ` `類的實例排序時,就必須提供我們自己的特殊方法cmp()``:
|
|
上述Student 類實現了cmp()方法,__cmp__用實例自身self和傳入的實例s進行比較,如果self 應該排在前面,就返回-1,如果s應該排在前面,就返回1,如果兩者相當,返回0。
Student類實現了按name進行排序:
|
|
注意: 如果list不僅僅包含 Student 類,則cmp 可能會報錯:
|
|
請思考如何解決。
python中len
如果一個類表現得像一個list,要獲取有多少個元素,就得用 len() 函數。
要讓len() 函數工作正常,類必須提供一個特殊方法__len__(),它返回元素的個數。
例如,我們寫一個 Students 類,把名字傳進去:
|
|
只要正確實現了len()方法,就可以用len()函數返回Students實例的“長度”:
|
|
python中數學運算
Python 提供的基本數據類型 int、float 可以做整數和浮點的四則運算以及乘方等運算。
但是,四則運算不局限於int和float,還可以是有理數、矩陣等。
要表示有理數,可以用一個Rational類來表示:
|
|
p、q 都是整數,表示有理數 p/q。
如果要讓Rational進行+運算,需要正確實現add:
|
|
現在可以試試有理數加法:
|
|
python中類型轉換
Rational類實現了有理數運算,但是,如果要把結果轉為int或float怎麼辦?
考察整數和浮點數的轉換:
|
|
如果要把 Rational 轉為 int,應該使用:
|
|
要讓int()函數正常工作,只需要實現特殊方法__int__():
|
|
結果如下:
|
|
同理,要讓float()函數正常工作,只需要實現特殊方法float()。
python中@property
考察Student類:
|
|
當我們想要修改一個 Student 的 scroe 屬性時,可以這麼寫:
|
|
但是也可以這麼寫:
|
|
顯然,直接給屬性賦值無法檢查分數的有效性。
如果利用兩個方法:
|
|
這樣一來,s.set_score(1000)就會報錯。
這種使用get/set 方法來封裝對一個屬性的訪問在許多面向對象編程的語言中都很常見。
但是寫s.get_score()和s.set_score()沒有直接寫s.score來得直接。
有沒有兩全其美的方法? —-有。
因為Python支持高階函數,在函數式編程中我們介紹了裝飾器函數,可以用裝飾器函數把get/set方法“裝飾”成屬性調用:
|
|
注意: 第一個score(self)是get方法,用@property裝飾,第二個score(self, score)是set方法,用@score.setter裝飾,@score.setter是前一個@property裝飾後的副產品。
現在,就可以像使用屬性一樣設置score了:
|
|
說明對 score 賦值實際調用的是 set方法。
python中slots
由於Python是動態語言,任何實例在運行期都可以動態地添加屬性。
如果要限制添加的屬性,例如,Student類只允許添加name、gender和score這3個屬性,就可以利用Python的一個特殊的__slots__來實現。
顧名思義,__slots__是指一個類允許的屬性列表:
|
|
現在,對實例進行操作:
|
|
__slots__的目的是限制當前類所能擁有的屬性,如果不需要添加任意動態的屬性,使用__slots__也能節省內存。
python中call
在Python中,函數其實是一個對象:
|
|
由於 f 可以被調用,所以,f 被稱為可調用對象。
所有的函數都是可調用對象。
一個類實例也可以變成一個可調用對象,只需要實現一個特殊方法__call__()。
我們把Person類變成一個可調用對象:
|
|
現在可以對 Person 實例直接調用:
|
|
單看 p('Tim') 你無法確定p是一個函數還是一個類實例,所以,在Python中,函數也是對象,對象和函數的區別並不顯著。